
Prediksi Kinerja Karyawan
Prediksi Kinerja Karyawan Berdasarkan Employee Engagement dan Employe Satisfaction [Sebuah Studi Kasus HR Analytics]
“Orang-orang HR tidak akan digantikan oleh data analytics, tetapi orang-orang HR yang tidak menggunakan data analytics akan digantikan oleh mereka yang menggunakannya”
— Nadeem Khan, Introduction to People Analytics: A Practical Guide to Data-driven HR
Daftar Isi
- Daftar Isi
- Overview
- Membangun Model Decision Tree untuk Prediksi Kinerja Karyawan
- Interpretasi Decision Tree
Overview
Kinerja karyawan merupakan faktor penting yang memengaruhi keberhasilan suatu organisasi. Organisasi yang memiliki karyawan dengan kinerja tinggi akan lebih unggul dalam persaingan dan mencapai objektif bisnis mereka secara lebih efektif. Namun, menilai dan memprediksi kinerja karyawan bisa menjadi tugas yang menantang. Faktor-faktor yang memengaruhi kinerja karyawan sangat beragam dan kompleks, mulai dari keterampilan dan motivasi individu hingga budaya kerja organisasi.
HR Analytics menawarkan pendekatan berbasis data untuk mengatasi tantangan ini. Dengan mengumpulkan dan menganalisis data yang relevan tentang karyawan dan kinerja mereka, organisasi dapat memperoleh wawasan berharga untuk membuat keputusan yang lebih baik tentang perekrutan, pengembangan, dan pengelolaan karyawan. Salah satu teknik yang ampuh untuk analisis data SDM adalah penggunaan Decision Tree.

Artikel ini membahas pengembangan model klasifikasi menggunakan Decision Tree untuk memprediksi kinerja karyawan. Model ini dibangun menggunakan HR Dataset dari Kaggle yang dapat diunduh dari sini. Data ini mencakup berbagai faktor yang dapat memengaruhi kinerja karyawan, dua di antaranya adalah tingkat kepuasan kerja (employee satisfsaction) dan hasil survei keterlekatan karyawan (employee engagement) yang saya gunakan pada project ini. Dengan menggunakan library Python yang populer seperti pandas dan scikit-learn, kita dapat membangun model prediktif untuk membantu organisasi dalam mengelola sumber daya manusia mereka dengan lebih efektif.
Membangun Model Decision Tree untuk Prediksi Kinerja Karyawan
Kode Python yang disajikan dalam artikel ini mendemonstrasikan pengembangan model Decision Tree untuk memprediksi kinerja karyawan di environment Google Colab. Berikut ini adalah penjelasannya langkah demi langkah.
Impor Pustaka: Blok kode pertama mengimpor pustaka yang diperlukan untuk analisis data dan pembuatan model. Library pandas digunakan untuk memanipulasi dan menganalisis data tabular, sedangkan pustaka google.colab saya pakai untuk mounting Google Drive ke workspace Google Colab.
import pandas as pd
from google.colab import drive
drive.mount("/content/drive/")Akses dan Persiapan Data: Kode selanjutnya mendefinisikan path ke file CSV yang berisi data HR yang akan kita gunakan. Fungsi pd.read_csv dari library pandas digunakan untuk membaca data dari file CSV ke dalam dataframe yang diberi nama hr_data. Terakhir, fungsi describe digunakan untuk melihat statistik dasar dari data, seperti rata-rata, deviasi standar, dan nilai minimum dan maksimum untuk setiap fitur.
hr_file_path = "/content/drive/MyDrive/_MLStudy/HRDataset_v14.csv"
hr_data = pd.read_csv(hr_file_path)
hr_data.describe()Definisi Variabel Target dan Fitur:
Variabel target dalam kasus ini adalah PerformanceScore, yang merepresentasikan kinerja karyawan. Fitur adalah variabel-variabel independen yang akan digunakan untuk memprediksi variabel target. Kode mendefinisikan dua fitur: EngagementSurvey dan EmpSatisfaction, yang diasumsikan sebagai faktor yang memengaruhi kinerja karyawan.
y = hr_data.PerformanceScore
hr_features = ['EngagementSurvey', 'EmpSatisfaction']
X = hr_data[hr_features]Pemilihan dan Pelatihan Model: Decision Tree dipilih sebagai model klasifikasi untuk memprediksi kinerja karyawan. DecisionTreeClassifier dari library scikit-learn digunakan untuk membangun model. Random state diset ke nilai numerik (dalam contoh ini 1) untuk memastikan replikasi hasil model. Nilai random state membantu menjaga konsistensi model saat dijalankan berulang kali.
from sklearn.tree import DecisionTreeClassifier
#specify the model.
#For model reproducibility, set a numeric value for random_state when specifying the model
hr_model = DecisionTreeClassifier(random_state=1, max_depth=4)
# Fit the model
hr_model.fit(X,y)Baris kode selanjutnya menggunakan fungsi fit untuk melatih model dengan data yang tersedia. Pada tahap ini, model mempelajari hubungan antara fitur-fitur (tingkat Employee Satisfaction dan hasil survei Employee Engagement) dengan variabel target (Performance Score).
Visualisasi Decision Tree: Setelah model dilatih, kita dapat memvisualisasikannya sebagai Decision Tree untuk memahami logika yang digunakan model dalam membuat prediksi. Pustaka matplotlib dan scikit-learn digunakan untuk menghasilkan visualisasi Decision Tree. Ukuran gambar dapat disesuaikan dengan kebutuhan menggunakan perintah plt.figure.
from matplotlib import pyplot as plt
from sklearn.tree import plot_tree
from sklearn.tree import DecisionTreeClassifier, export_graphviz
import graphviz
from subprocess import call
plt.figure(figsize=(20,10)) # Adjust the figure size as needed
plot_tree(hr_model, feature_names=list(X.columns), class_names=y.unique(), filled=True, rounded=True)
plt.show()Interpretasi Decision Tree
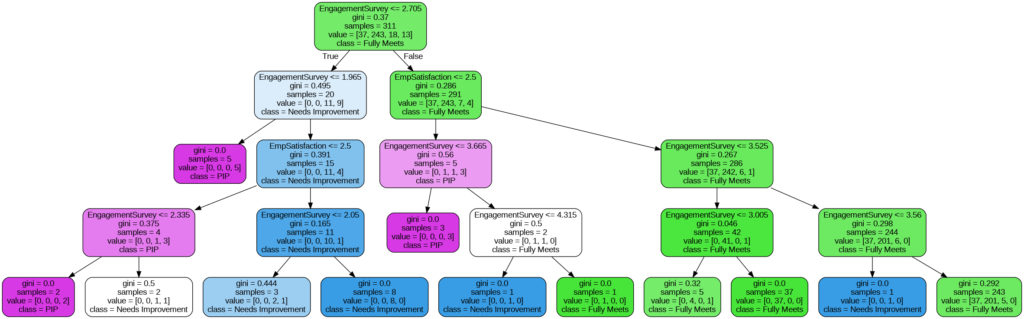
Visualisasi Decision Tree yang dihasilkan akan menampilkan serangkaian aturan if-then yang menggambarkan bagaimana model mengklasifikasikan data baru. Setiap cabang pada Decision Tree mewakili keputusan yang dibuat berdasarkan nilai fitur, dan daun (ujung cabang) mewakili kelas yang diprediksi (dalam kasus ini, tingkat kinerja karyawan).
Berdasarkan Decision Tree pada model ini, jika nilai Engagement Survey kurang dari 2,70 dan nilai Employee Satisfaction kurang dari 2,50, maka kemungkinan besar Performance karyawan ada pada kategori PIP (dibutuhkan Performance Improvement Plan). Sebaliknya, jika nilai Engagement Survey lebih besar dari 3,56 dan nilai Employee Satisfaction lebih besar dari 2,50, maka kemungkinan besar Performance karyawan akan masuk pada kategori Fully Meet.
Menarik pula untuk disimak bahwa karyawan dengan Engagement Survey di bawah 1,9 diprediksi kuat memiliki Performance pada kategori PIP.
Evaluasi dan Peningkatan Model
Penting untuk dicatat bahwa project ini adalah Decision Tree dengan menggunakan data dari Kaggle, dan mungkin tidak sempurna. Kasus di setiap organisasi bisa jadi berbeda, dengan faktor-faktor yang masih dapat dieksplorasi lebih jauh. Perhatikan pula bahwa model pada kasus ini memaksa Decision Tree maksimal hingga 4 level. Eksplorasi lebih dalam lagi masih dapat dilakukan untuk poin-poin di mana randomness data (yang ditunjukkan oleh nilai gini) belum mencapai 0.0.

Pelajari langkah mudah memahami dan memanfaatkan data bagi UMKM dari e-book ini. Klik di sini